常被用的GAN比喻,假鈔製作(生成目標樣本)需要詳細研究被偽造鈔種的特徵(訓練樣本數據的特徵),然後進行偽造(生成)。這個過程有2點需要說明:
那麼製作偽鈔需要一些怎樣的特徵呢?這時候第二個角色驗鈔人(判別器)就出場了。偽鈔製作者只需要知道驗鈔人會如何檢驗鈔票的真偽(關鍵特徵),然後儘量去滿足檢驗過程,這樣製作出來的鈔票才是能“以假亂真”的鈔票。在模型訓練中,不可能在機器前放一個人,專門告訴模型說“這個樣本生成的好”或者“這個樣本不及格,重來”。更關鍵的一點是,模型也聽不懂人話啊。 所以Ian Goodfellow給出了答案:讓模型來判別,讓模型來反饋,讓模型來學習。
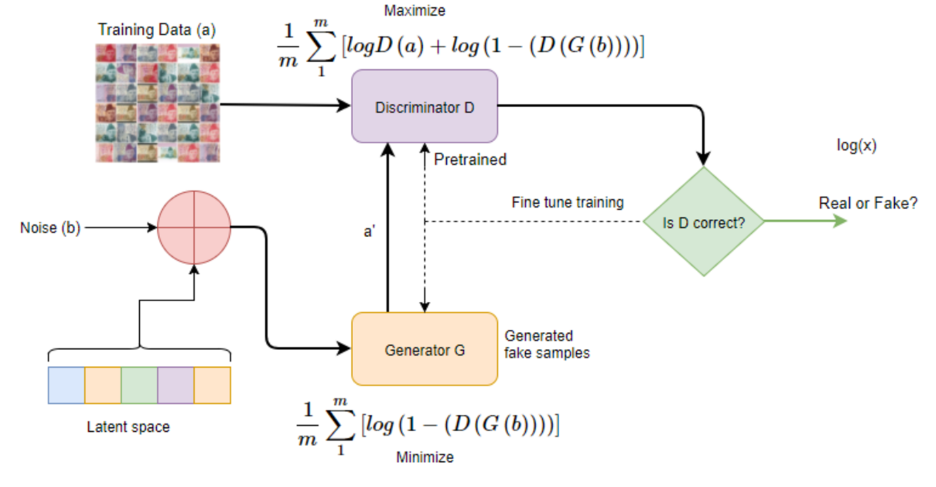
先簡單介紹一下這張圖裡的各個元素。link
Latent Space :中文譯名應該叫隱藏空間,可以理解為抽象的集合空間,裡面的元素為一個個生成樣本的主題,通常用向量表示。例如現在的生成器是用來生成家具圖片的,那麼它的Latent Space就是所有的家具,包括桌子,椅子,沙發等等。
Noise:輸入噪聲。是它賦予了生成器生成可變樣本的能力。因為生成器本質上是個函數,輸入確定的情況下,輸出也會確定。如果沒有噪聲輸入,生成器會針對同樣的特定輸入(按照上圖來說就是只輸入Latent Space的信息)產生依賴,模型會產生嚴重的偏置,而且無法保證在輸入與之前的特定輸入不一致時會產生什麼樣的後果。換句話說,這個噪聲可以提升模型的泛化能力。
Generator:生成器。一個將輸入空間投影到輸出空間的函數。在深度學習的領域裡,這個生成器可以由任意的可導函數組成,因為整個GAN框架都是基於Backpropagation反向传播算法進行學習的。
Training Datas (Real Samples):真實樣本。就是自然存在的真實數據,區別於生成器生成的樣本數據。
Discriminator:判別器。最後的決定者,判別輸入是來源於真實數據還是來源於生成器偽造的數據。是前向運算的終點,它的輸出將會轉化為生成器以及本身的loss,然後聯合訓練。
可以看到圖中有一個別緻的開關,用來選擇判別器接受的數據來源。所以可以看到生成器並不是每一次數據流轉都會受到訓練,而是k次訓練判別器之後,訓練一次生成器。這個比例是可以認為調節的。
在GAN中,判別器部分用作識別圖像的分類器。 但是,在學習過程中,生成器和判別器都相互協調。 生成的圖像被發送到判別器模塊以對它是偽圖像還是真實圖像進行分類。 如果可判別,則判別器將產生其輸出,如果不能判別,則模塊會將其發送回生成器以重新生成圖像。 根據收到的反饋,生成器改善其投射並創建圖像。 這個過程一直持續到兩個模型都可以正確生成和分類同一圖像為止。

